Buying physical hardware was a new step for WonderProxy, it’s hard to say that we rushed into it, this being our third year, but it sort of feels that way. We’re operating around 100 servers around the world right now, but all of them are either virtual servers, or dedicated machines we’re renting from providers. Having a UPS guy drop off a rather large box one day was a big change.
Everything has worked out well, but there was a few steps that could have gone more smoothly, this post is half note to myself on what to do better next time, and half for you.
Buying Hardware
- As far as I can tell the Dell & HP websites have been largely designed to be horrible, in hopes of routing you to a sales person. I tried to fight this, but it was pointless. Phone someone at one of those companies and save yourself several hours.
- Watch for extras on the quote, your sales person will likely work your specifications, then insert the most expensive options around it, things like 24/7 hardware replacement with a 4hr SLA, fancy cable management systems, etc.
- Your data centre will have power requirements. Your phone rep may be able to help you there, Dell’s UPS website is also capable of turning your server specifications into amperage.
- Remote management cards are helpful, but you’ll either need to set up pass-through on the NIC (if your card supports it) or have multiple drops to reach it.
- Check each component for compatibility with your operating system if it doesn’t ship installed. We’re using Debian, and had a mild panic attack before we found drivers for our Raid controller in Debian testing.
Hosting
- Your hosting provider will sell you bandwidth as a 95th percentile. That means they’ll sample how much bandwidth you’re using on regular increments (say every 15 minutes), sort those results biggest to smallest, delete the top 5% then charge you the next one. Unless you’re buying a lot of bandwidth you’ll probably end up paying more here than you would on a dedicated box by the GB.
- Hosting space comes in either U increments (1U, 2U, 4U, etc) or rack portions (full rack, half rack, quarter rack, eighth rack (octal). If you’re buying directly from a provider you’re likely going to need to over-buy if you’re only racking one server.
- Providers also care about power usage they will likely tell you something like 8 AMPS. You’ll need to spec your server out appropriately.
- The number of network cables and power ports inside your unit will also matter, there’s no point in having a redundant power supply if you’re only going to be able to plug one in.
- You will need to plan your move in date, your provider may need a lot of paper work signed and then a few more days before this happens. Talk to your sales rep about dates, and SLA for setting up new space. It may be as long as a week between getting your paper work in order and being able to move in.
- Find out how your server will be mounted, there appears to be both round and square holes. As we learned when we were four, you need to match the right peg to the right hole. If you’re renting a very small fraction of space (like an octal) you may not have any mounting brackets at all, instead just letting things rest on the sheet metal between clients.
- Your sales guy may not manage things once you’ve signed up, you may be handed off to the network team. Try to keep track of who knows what, if you’re racking your server and have a problem sales guy can’t help (and probably doesn’t answer the phone after hours).
Visiting the Data Centre
- You’ll need ID, your network guy should be able to describe the requirements
- Depending on how many servers you’re bringing in, you may be able to use the front door, or the loading dock.
- Ours had a nice man-trap on the way in, first door needed to close before the second would open
- It will be loud in the server room, ear plugs would be prudent
- A flash light might help see things, there’s decent lighting but you’ll likely have stuff on top and below you
- There should be a monitor, keyboard, and mouse on a trolley somewhere for configuring things
- There may not be wifi, or even 3g inside
- Pre-configuring your IP details stuff would be prudent, there will not be DHCP
That in hand, hopefully your server buying and racking experience will go smoothly.
Andrew Quarton developed a nifty little visualization built using the Where’s it UP API called GeoPing. Go take a look then come back.
Our technology stack for the API includes supervisor to run workers, and gearman to manage our job queue. We’re normally running 25 workers to manage the queue. Work tends to come in chunks, and that number of workers has been able to keep the queue minimal or at zero.
Since it’s such an nifty tool, it made the front page of Hacker News today, which led to a few problems on our end. The number of jobs launched for each person hitting the GeoPing tool was rather high, enough to fill all the current workers. When many people started hitting the GeoPing tool in rapid succession the queue built and built. At one point Gearman reported 13,000 jobs in the queue.
Noticing this I quickly changed the number of desired workers in supervisor from 25 to 100, than used /etc/init.d/supervisord restart to apply the changes. That didn’t seem to affect the queue, so I tried 250 workers, used restart to apply the changes once more, and watched. Then I noticed something the restart option wasn’t launching the extra workers I wanted. Running /etc/init.d/supervisord stop, then start did. Then the queue finally started to recover. I kept an eye on the queue with a quick and dirty shell command from stack overflow.
(echo status ; sleep 0.1) | netcat 127.0.0.1 4730 -w 1From our side, I think a few things went wrong:
- We didn’t have tooling in place to warn us when the queue broached reasonable limits
- We hadn’t documented the proper way to increase workers (stop/start not restart)
- Our graphing system seems to have a hard coded max value, hiding valuable data
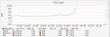
Having either of those first two items in place would have allowed us to respond to the issue much more quickly.
We're working on them :)
I invested a portion of my day heading down to our data centre, and yanking a drive out of our newly racked server, and watching to see what would happen. The answer was: not much. The system kept merrily computing along, but it also failed to warn us that it had lost a drive. Some configuration tweaks later, I repeated the process, and my mailbox was quickly filled. Success.
I did this for two reasons: I wanted assurance that our raid controller had been properly configured, and that things would continue operating normally if we lost a drive. I also wanted to ensure that should we lose a drive we'd be notified, redundancy is worth little if actions aren't taken to correct problems that cause it to be lost. Today confirmed the first, and revealed problems in the second. Huge Success.
If you're going to perform the same task, a few pieces of advice:
- Do it before there's critical production software running on it, at least the first time
- Your raid controller will need to rebuild the drive after it's been pulled. This will take a while, and kills your redundancy (or a portion thereof) while it's happening. If you need to repeat the test pull the same drive each time to avoid real problems.
- Work to ensure that problem notifications leave the affected system as quickly as possible. If the only copy of an alert sits on the box that's having issues, you may lose it as well.